



在《0基础学习区块链技术——入门》一文中,我们结合可视化工具,直观感受了下层区块的结构和链的脉络。
在本文中,我们将抛弃以往的知识,从0开始思考和推导,区块链技术可能是如何构思的。
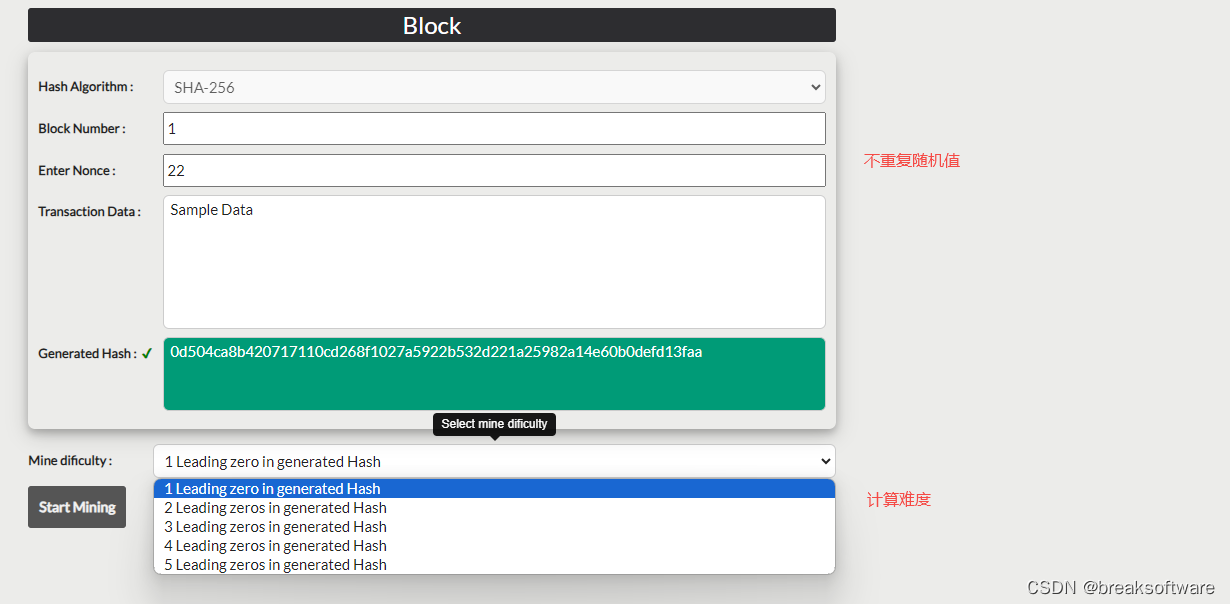
总的思维来说,我们把信息保存在一个“中心”,方便高效。但问题是很容易篡改。因为只要征服了“中心”这样的对象,就可以修改所有的信息。(下图中:人脸代表用户,红色六角星代表攻击,红色方块代表被篡改的数据。)
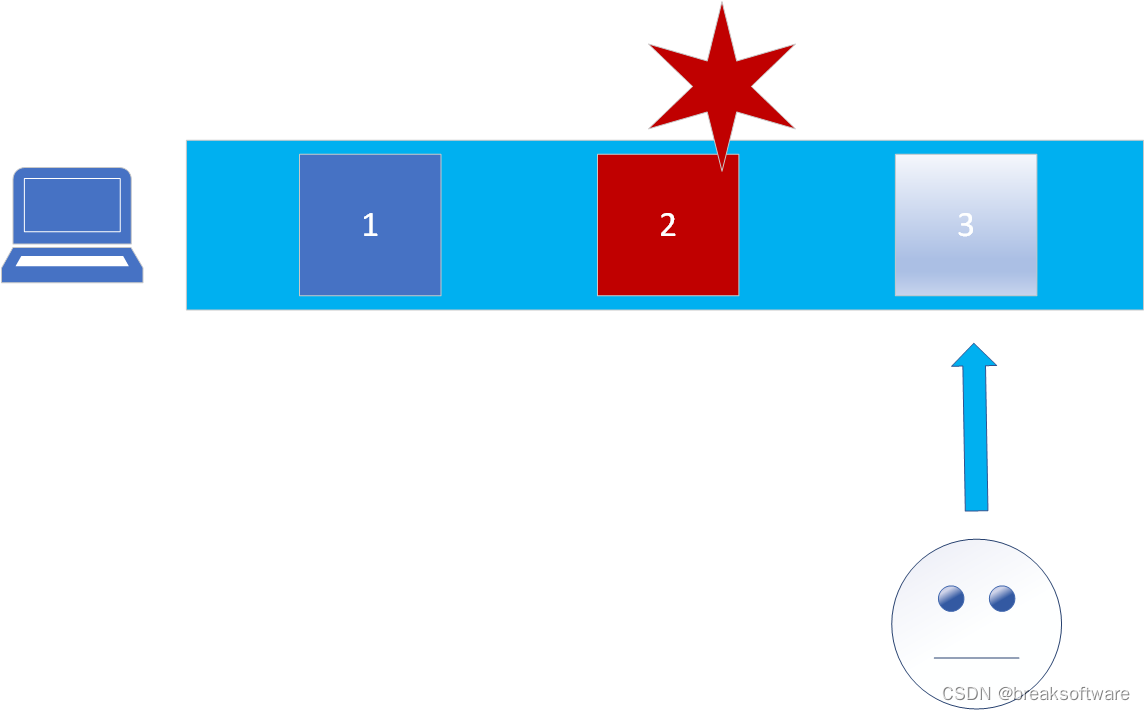
那怎么会更安全呢?一个简单的思路就是加一个“中心”。
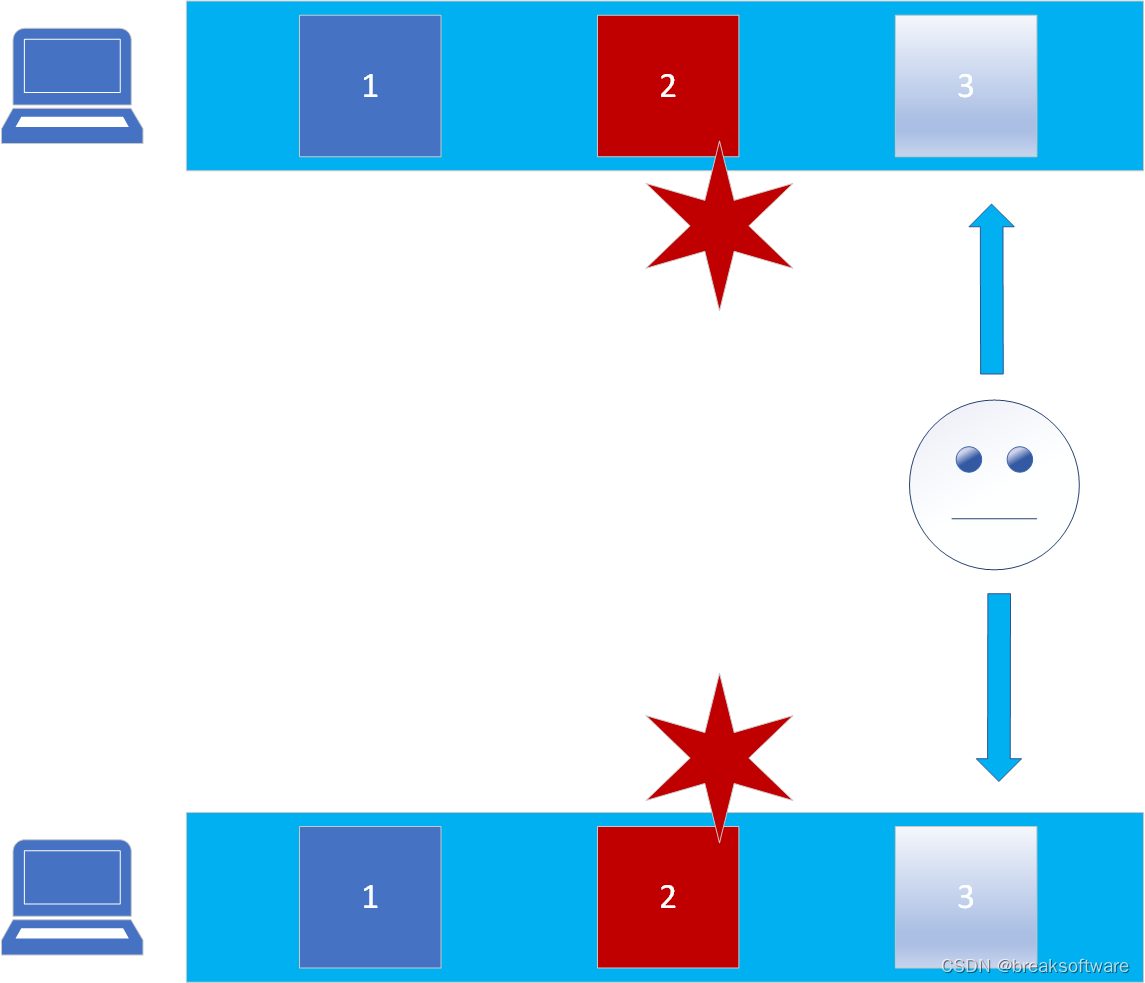
这样攻击者需要征服两个“中心”才能达到修改历史数据的目的。
按照这个思路,如何更安全?对,多加几个“中心”。这样,攻击者需要征服更多的“中心”来修改数据。
随着“中心”的增多,他们变得越来越不“中心”。因为每个“中心”都是平等的,没有谁的权重高,也没有谁的权重低,所以“中心”这个概念就没了。这就是“去中心化”。
如何防止篡改历史数据?其实“预防”不太可能。我们唯一能做的就是“增加篡改成本”。像上面增加“中心”的数量,并不能避免所有的“中心”都被征服,只是增加了被征服的难度。
那么如何增加篡改的成本呢?一个简单的想法是加密数据。但是,数据加密需要密钥。如果这个密钥被盗,就会导致整个方案,或者一个数据中心的所有数据都被攻克。
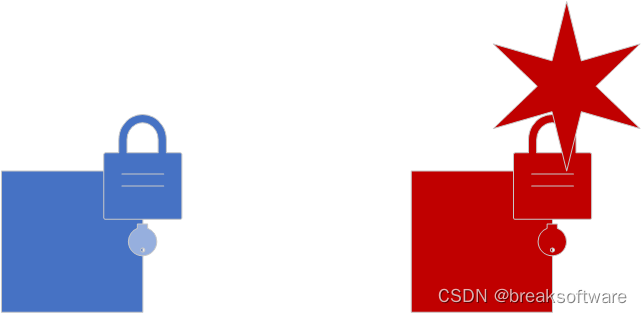
关键问题是,被篡改后,我们需要对比其他“中心”的解密数据,才能感知该中心的数据有问题。
j 1FPRICR
如何快速感知数据变化?那就是指纹计算。也就是说,我们为数据计算一个唯一的指纹。一旦数据有任何变化,之前的指纹就会失效。
这样,如果篡改者修改了历史数据,那么历史数据所在的数据区的指纹将失效,此时篡改者需要重新计算新的指纹。
在区块链技术中,用于指纹计算的哈希算法包括SHA-256等。不同算法计算出来的数据(指纹)长度不一样,但是同一算法计算出来的长度是一样的。需要注意的是,目前的哈希算法都存在碰撞的可能性(即不同的数据可以计算出相同的哈希值),但概率很低。
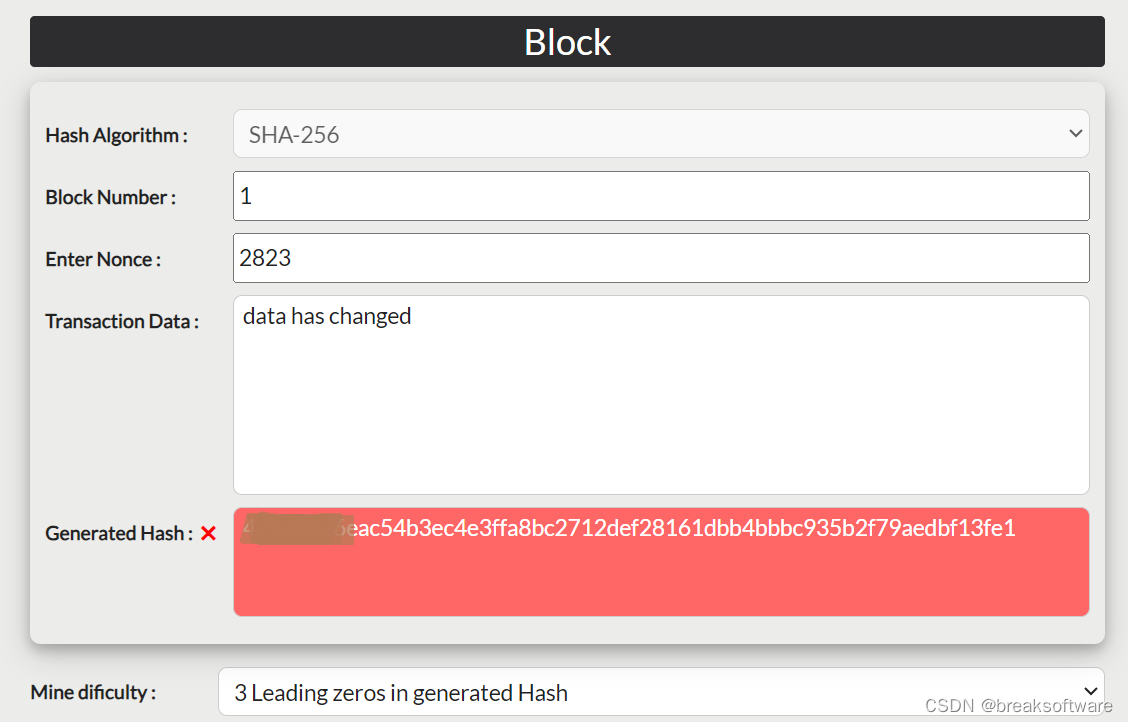
如果篡改者的手速非常快,可以一下子算出Hash。这不就说明我们的方式很容易被征服吗?我们做什么呢增加算法难度。因为哈希算法是不可预测和不可逆的。我们只能用“暴力”计算。这样,我可以提出一些规则,比如要求散列值满足某些条件。但是因为数据和哈希值是一一对应的,所以如果需要改变哈希值,就需要改变原来的数据。所以我们引入Nonce的概念,它会成为原始数据的一部分,这样Hash值就可以随之改变。但是这种变化是不可预测的,也就是在我们不知道Nonce为什么值得的时候,计算出来的Hash符合一定的规律。我们唯一能做的就是算出来,看看值是否符合规律。
一个容易想到的规则是要求计算出的哈希值的第一个或最后一个数字为0。
在《0基础学习区块链技术-入门》中,我们看到例子中有五种规则,实际的规则会更复杂,需要的暴力计算时间也会更长。
如果我们把数据保存在一个加密的区域,那么在添加新数据的时候需要对原始数据进行解密,添加完新数据之后再进行加密。
7HXdW 1 1W
这个过程有点繁琐。
有更简单的方法吗?一条数据可以加密一次,不会和历史数据混在一起。但在防止篡改这一块,这个方案似乎无能为力。
所以我们回到指纹方案。
所以要采集所有数据的指纹?或者对单个数据进行指纹识别?(其实都不是)
如果所有的数据都被指纹化,我们将面临一个“以有限反无限”的问题。因为随着数据的增加,每次把所有的数据都计算一次会变得越来越困难。比如现在有几百克的比特币交易数据。如果每次新数据进来都要对这几百克的数据进行哈希处理,那么对机器资源的消耗会更大。
所以给一个单独的数据采集指纹?似乎只能在检查单个数据时发现篡改(因为数据的Hash因为篡改而发生了变化),而不能很快发现整个数据已经变得不可信。
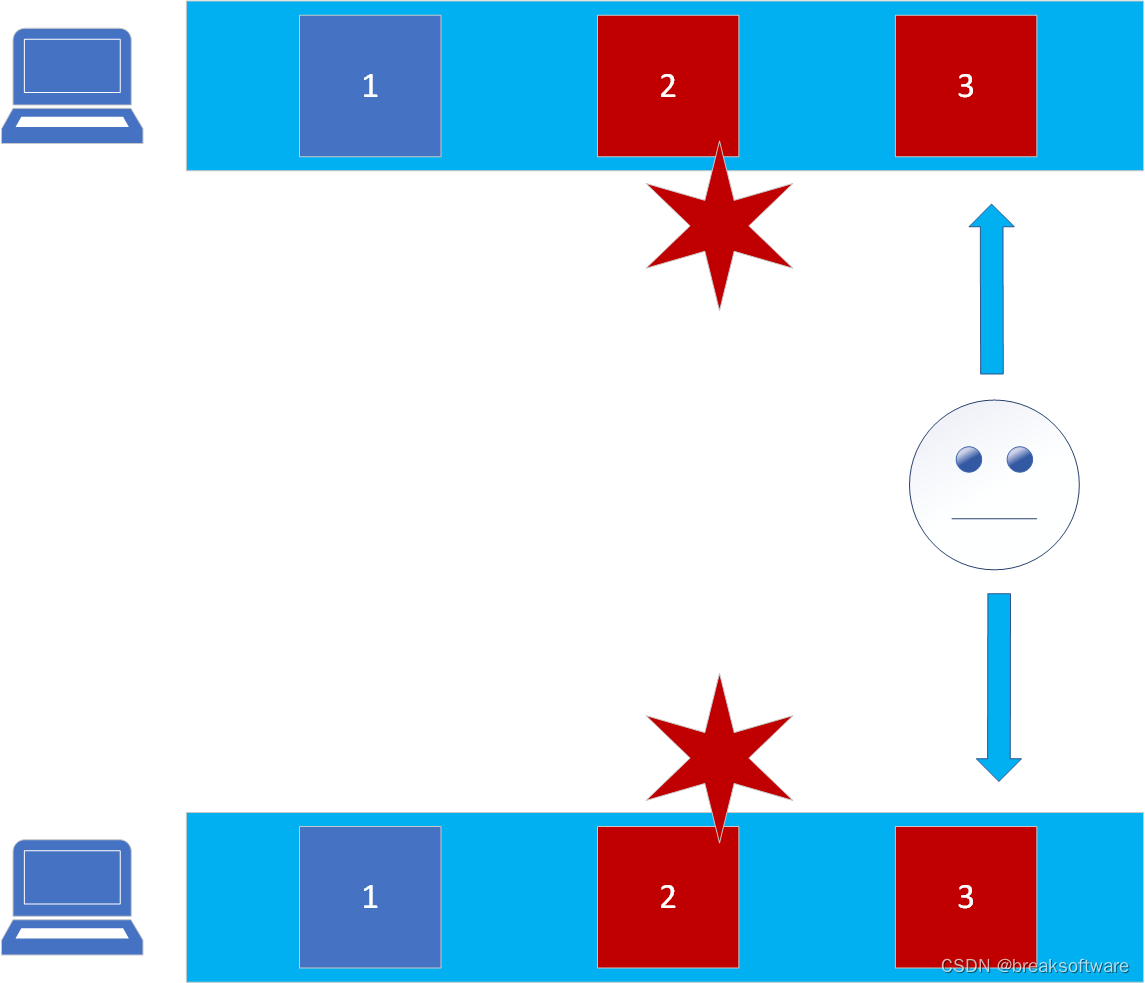
所以基于计算机数据结构的一些思想,数据可以通过链式关系链接起来。充当“枢纽”的是前一个块的散列。

如果链中某个块的数据发生了变化,那么它的Hash也会发生变化,后面那个块的Pre hash仍然指向原来的值,这样区块链的链关系就断了,链就有问题了。

注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论